AI systems recommend your competitors more than you.
Answerability is a long-form intelligence report on how ChatGPT, Claude, Gemini, Perplexity, and Grok answer buyer questions in your category — and an operational roadmap for closing the gap.
AI systems are becoming the pre-sales layer.
Buyers increasingly evaluate providers inside ChatGPT, Claude, Gemini, Perplexity, and Grok before they ever visit a website.
An illustrative reconstruction of what most companies see when they audit a high-intent buyer query in their category. A real diagnostic shows the actual prompt, the actual competitors, the actual domains, and the exact source paths the engines surfaced — across all five engines, across all 60 prompts.
We are entering a world where recommendation layers matter more than rankings.
Three independent failure modes.
A page can fail on any one pillar for reasons the others can't fix. Answerability is the composite; we score every cited URL on its three pillars — Content, Retrieval, and Trust — separately. Together they map your Retrieval Surface — the slice of the web AI can actually reach and trust.
Do you have content that answers what buyers actually ask — in a form an engine can lift?
Example failure: buyers ask the engine what it costs; the only page on the topic says "contact us for a quote."
Can AI systems access, crawl, parse, and structurally understand your content?
Example failure: a sample study living as a PDF with no HTML wrapper, no schema, and no extractable text.
Do AI systems treat your content as cite-worthy when an answer is on the line?
Example failure: no named methodology reviewer, no credentialed engineer attached to claims, no third-party corroboration.
Any one of the three can be why an engine skips you. The hard part isn't the fix — it's knowing which one.
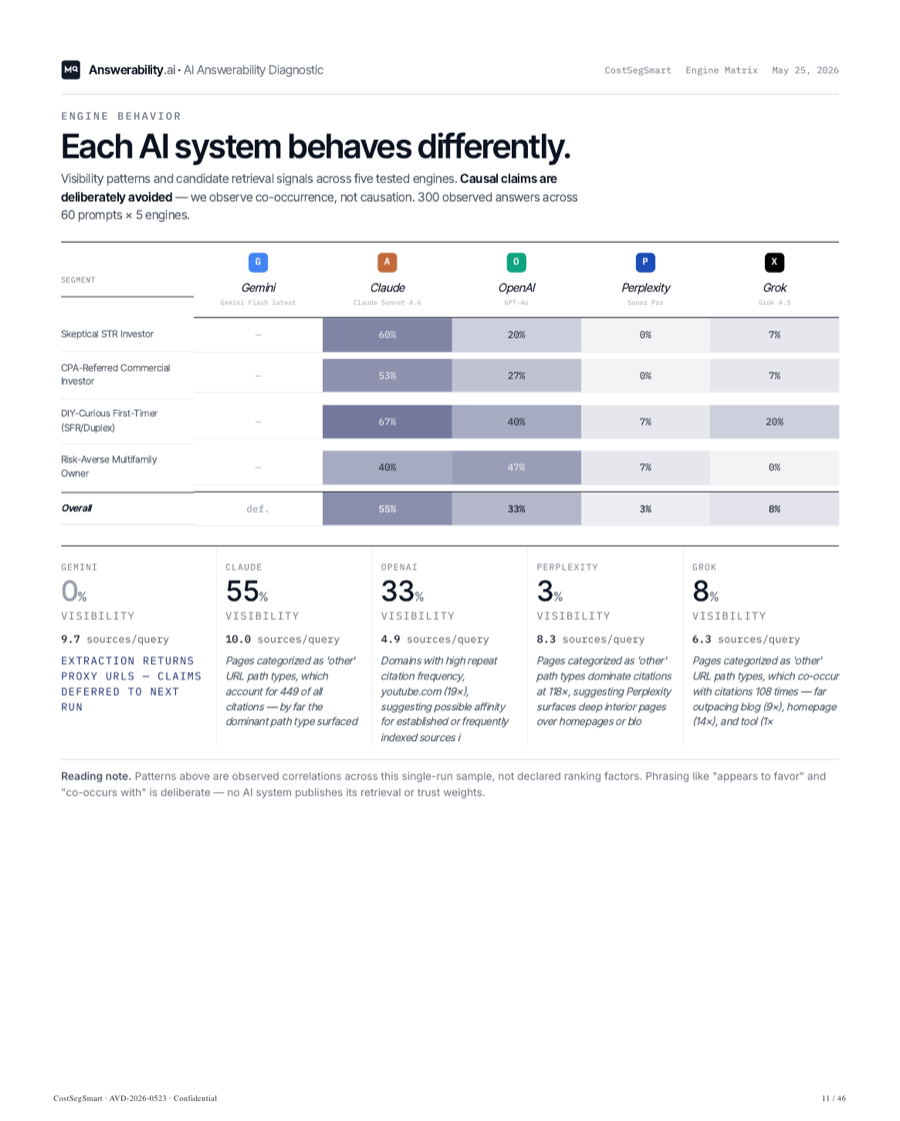
Each AI system behaves differently.
Patterns observed across our standing prompt set, updated monthly. Causal claims are deliberately avoided — these are observed correlations, not declared ranking factors.
| Engine | Visibility | Appears to favor | Typical failure mode |
|---|---|---|---|
OChatGPTOpenAI · GPT-4o |
38% |
Structured author entities, dated content, deep-linked sub-pages — commonly present among cited pages. | Weak author entity. No Person schema or sameAs on service pages. |
AClaudeAnthropic · Sonnet 4.6 |
51% |
Methodology depth, quote-safe paragraphs — observed to co-occur with cited results. | Thin “how we work” documentation. Few 40–80 word extractable chunks. |
GGeminiGoogle · 2.5 Pro · with Search |
0% |
High external entity corroboration — Knowledge Graph, Wikidata, news mentions commonly present among cited pages. | No Wikidata item, weak entity graph, Google Business unverified. |
PPerplexitySonar Pro |
27% |
Primary-source citations — statutes, regulators, peer-reviewed work — commonly present in cited results. | Unsourced numerical claims. No hyperlinks to primary references. |
XGrokxAI · Grok 3 |
14% |
Recency, social and trade-press surface, active publishing cadence — observed to co-occur with cited pages. | No recent published mentions. Last cornerstone page dated 11 months ago. |
Pattern from a recent engagement — numbers shown are illustrative and will differ for every category. Single-run observational sample; findings describe co-occurrence within this engagement’s prompt set, not declared ranking factors. Last updated May 23, 2026.
A long-form intelligence dossier.
Nine chapters across executive summary, framework, buyer segments, engine behavior, competitor landscape, URL work orders, trust gap, 30-day roadmap, and methodology appendix. Designed to be printed, circulated internally, and revisited operationally. Then refreshed monthly as Visibility Intelligence.

Three pages from a sample diagnostic, illustrative (CostSegSmart) — executive summary, the per-engine visibility matrix, and the trust-signal gap. The full report runs nine chapters, ~45 pages.
Five industries, instrumented.
Real cross-engine capture data on five sectors selected for ICP fit and competitive-structure variance — from frozen (one consensus winner across five engines) to fragmented (no overlap at all). Each brief carries the underlying capture, the buyer-question prompts, and the territory map.
Commercial Insurance Brokers
72 brokers named across five engines, no unanimous winner on any commercial prompt. ChatGPT defaults global; Perplexity, Grok lean specialist.
Read the brief → Frozen top · B2B SaaS + industrialB2B SaaS & Industrial Manufacturing
Procore, ServiceTitan, Lincoln Electric unanimous at rank 1 across all five engines. Second tier (ERP, motion control, pumps) swaps order by engine.
Read the brief → Fragmented · wealth managementWealth Management & RIAs
Two distinct HNW shortlist universes — trust-bank lean (ChatGPT, Claude) vs. independent-RIA lean (Perplexity, Grok, partial Gemini). Local RIAs largely invisible.
Read the brief → Brand-dominant · personal injury lawPersonal Injury Law Firms
Morgan & Morgan dominates ChatGPT/Claude/Gemini at ~83%; Perplexity tilts to mass-tort specialty firms. Observational language under ABA Model Rule 7.1.
Read the brief → Hybrid · multi-location home servicesMulti-location Home Services
Two patterns in one sector. Restoration is brand-dominant (SERVPRO, Paul Davis); HVAC/plumbing franchises still fluid across engines.
Read the brief → The full hubSee all five industries
Category-temperature spectrum, capture methodology, and the path to a sector you don’t see listed here.
Go to the hub →Every page becomes a work order.
A scored URL becomes a scoped fix. Each work order names the bottleneck, the action, the effort, and the affected buyer queries — pulled directly from the report.
Every engagement begins with the buyers, not the keywords.
Before a single prompt runs, we construct the buyer archetypes for your category. Each one becomes a named profile with decision criteria, language patterns, and the queries they actually type. Visibility failures are often segment-specific — the same site can succeed with one buyer type and disappear with another.
The fields are constant. The content is built from your buyers.
Profile
Demographic and situational detail: age, role, portfolio or business stage, geography, discovery channel, advisor relationships.
Decision criteria
What this buyer stress-tests before short-listing a provider. Specific to their domain — credentials, methodology, audit history, pricing transparency, peer signals.
Search behavior
Representative queries this buyer types into AI engines — the awareness, comparison, risk, pricing, and fit questions that drive 80% of their pre-purchase research.
Bottleneck axis
Which of Retrieval, Trust, or Answerability is suppressing your visibility with this archetype — and the specific trust signal most absent from your pages.
The audit math, made visible.
Every engagement produces 300 observations across the five engines — one for every prompt × engine pair.
Example from one engagement — one of four archetypes built for a specialty professional-services firm. Yours will look nothing like this; the fields are constant, the content is built from your buyers.
The Risk-Averse Established Buyer
- StageEstablished operator, 10+ years in business
- Decision lensAudit / risk defensibility over savings or speed
- Advisor stanceBrings options to her professional advisor before deciding
- WillingnessWill pay a premium for peace of mind
- Verifiable credentials of the person actually signing the work
- Documented outcomes in audits or examinations, not just claims
- Specific scope of post-engagement support — hours, who responds, who pays
- How methodology aligns line-by-line with the regulator’s published guidance
- most established [provider] with audit history
- [provider] firms with zero adverse rulings
- what is included in [provider] post-engagement support
- regulator-defensible methodology for [domain]
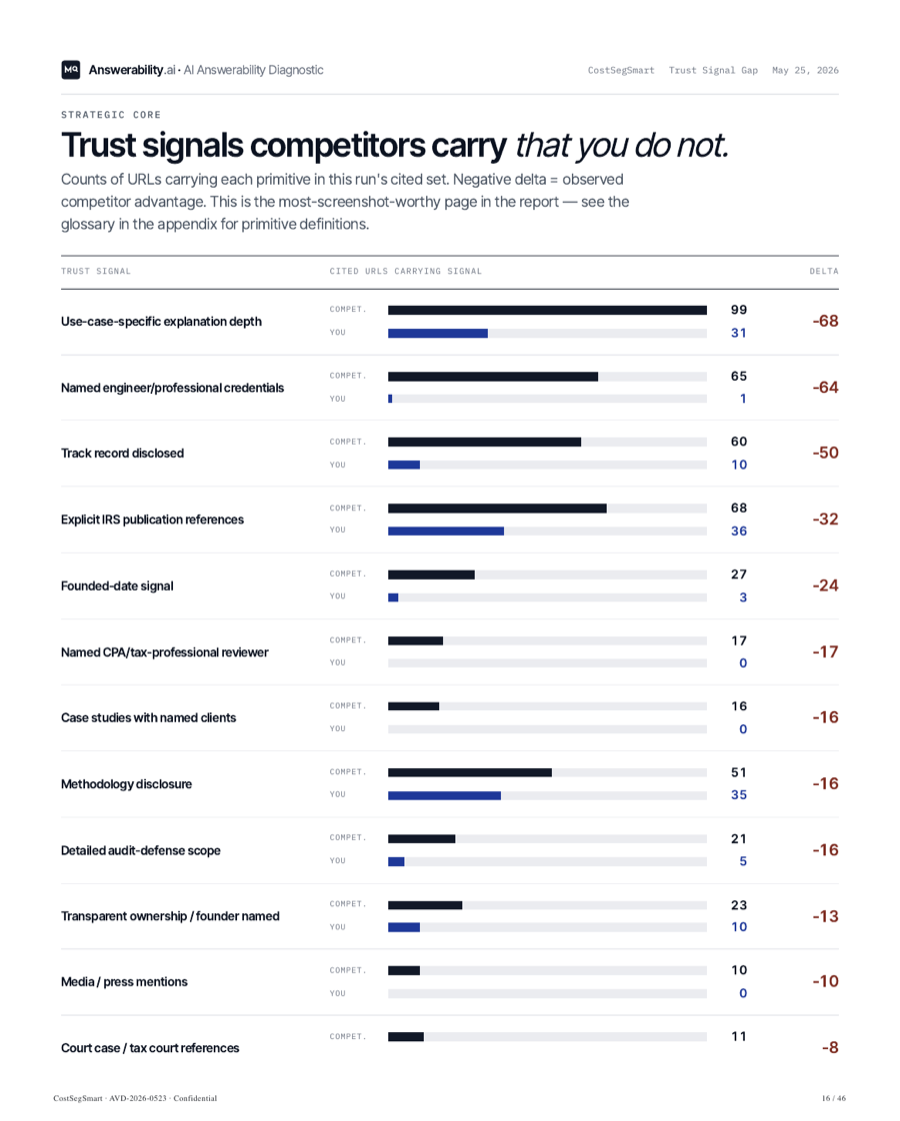
Named credentialed reviewer attribution −47 vs competitors. She never sees a verifiable human on our pages.
How we build these. Archetypes are constructed from your stated ICP, your top-of-funnel CRM patterns, sales-call transcripts where available, and language pulled from adjacent buyer communities — Reddit, vertical forums, industry trade press. Each archetype produces 15 prompts across awareness, comparison, risk, pricing, fit, and post-purchase stages. No keyword tools. No generic SEO term lists. The prompts are the questions actual buyers are typing into ChatGPT, Claude, Gemini, Perplexity, and Grok.
Built for companies losing visibility they didn't know they had.
If you're already showing up in AI answers, you don't need us. If your competitors are showing up and you aren't — and you can't explain why — this report explains why.
You’re losing referrals to competitors with named experts on every page.
AI engines cite review sites instead of your category pages.
Trust signals determine the shortlist before a discovery call. Read the diagnostic →
AI engines are reading your “X vs Y” pages and citing the competitor.
Three ways to work with us.
Each engagement produces a written artifact. None of them produce a dashboard. All of them are confidential under MNDA.
Start here. The long-form intelligence report — then it keeps running as monthly Visibility Intelligence. Each month a report, a playbook, and built pages. Cancel anytime.
- Long-form report across 5 engines — scoring, competitor landscape, work orders
- Excel playbook: buyer queries → the content to create & how to structure it
- Two deploy-ready example pages, built and optimized for your buyers' questions
- Then monthly: a delta report, a refreshed playbook & two more pages
- 45-minute walkthrough — cancel the monthly anytime
The full diagnostic — then we build the fixes. Over four weeks we produce the highest-leverage content, retrieval, and trust assets the report identified, ready to ship. Your developer does the final deploy; we verify each fix went live and is read correctly.
- Everything in the Diagnostic
- Up to four 60-min working sessions, scheduled in advance
- We build it for you: content rewrites, JSON-LD schema, llms.txt
- Plus a methodology page and your entity-graph plan
- Delivered ready to ship — your developer does the final deploy
- Then monthly Visibility Intelligence ($950/mo, cancel anytime)
When you'd rather we implement directly on your site, or run something larger or ongoing. We do the work; the engagement is scoped to you. Includes the Diagnostic and monthly Visibility Intelligence.
- We implement directly on your site
- Larger or ongoing scope than a single Sprint
- Includes the Diagnostic + monthly Visibility Intelligence
- Mutual NDA and a scoping call first
How an engagement works.
Three discrete steps. Each has a defined artifact. The thing you're paying for is the written work, not the meeting time.
Scope the audit.
You share your domain, top three competitors, and the buyer questions that matter most. We build the prompt set together and run the audit across all five engines.
Deliver the report.
You receive the dossier by email as a PDF, plus a 45-minute walkthrough. Every URL on your site that appeared in any cited result gets scored and gets a work order.
Track the lift, every month.
Each month we re-run the prompt set against your updated site and deliver a delta report, a refreshed playbook, and two more built pages — what moved, why, and what's next. Cancel anytime.
How the audit runs.
A standing protocol, versioned and updated as engine behavior shifts. Findings describe observed patterns within a bounded sample — not universal ranking rules.
Answerability is a methodology-first research practice. The principal investigator is an economist and AI researcher whose prior work spans applied machine learning, internet platforms, and expert analysis in technology-related matters.
Engagements are produced as structured research artifacts using the proprietary Answerability framework — scored across its three pillars, Content, Retrieval, and Trust, against the standing 60-prompt audit set, and reviewed before delivery. The framework is formalized in our working primer and its three pillar notes.
The rubric extends the information-retrieval evaluation tradition (TREC, 1992–) to LLM-mediated answers. See Ding et al., Citations and Trust in LLM Generated Responses, AAAI 2025 — which finds that citations raise user trust even when random, while verifying those citations reduces it. The rubric is designed against that failure mode.
Questions buyers ask first.
If yours isn't here, write to hello@answerability.ai.
Generative engine optimization is the operational practice of measuring and improving how AI search systems — ChatGPT, Claude, Gemini, Perplexity, and Grok — retrieve, trust, and cite a company’s content when answering buyer-intent queries. It overlaps with technical SEO on crawl access and structural clarity, and diverges from it entirely on entity-graph presence and extractable passage quality. In the May 2026 Answerability Index pilot, the five engines named 72 different commercial insurance brokers on the same six buyer prompts — 0.38 inter-engine overlap (Jaccard), no unanimous winner on any prompt. SEO-style ranking signals do not predict which firms get named in that fragmented answer set, which is why measurement and instrumentation are the entry point, not better keywords.
Our working primer formalizes the distinction and the framework we score against: Generative Engine Optimization: a working primer.
Traditional SEO optimizes for a ranked list of links — title tags, backlinks, content depth, page experience. AI-mediated discovery skips the list. ChatGPT, Claude, Gemini, Perplexity, and Grok read the relevant sources, synthesize an answer, and recommend a short set of providers — usually without showing the user a SERP at all. In the May 2026 Answerability Index pilot, the five engines named 72 different commercial insurance brokers on the same six buyer prompts, with 0.38 inter-engine overlap and no unanimous winner. SEO-style ranking signals do not predict which firms get named: industry research (Ahrefs, December 2025, n=75,000 brands) found Domain Rating correlates with AI citations at roughly 0.27, while unlinked brand mentions correlate at roughly 0.74 — about three times stronger.
The three pillars of Answerability — Content, Retrieval, Trust — were built for the answer-layer behavior, not the rank-list behavior. There is meaningful overlap with technical SEO on the Retrieval pillar. There is essentially none on Content and Trust.
No. AI engines do not publish their retrieval or ranking weights, and any honest practice has to refuse a guarantee. What we do guarantee is the artifact: a scored URL ledger, scoped work orders, a sequenced roadmap, and monthly Visibility Intelligence against the identical prompt set so movement is measurable. In our own dogfooding — see /insights/who-to-hire-for-ai-search — we ran the Answerability Diagnostic on ourselves in May 2026 against the prompt “who should I hire for AI search”: Grok recommended four competitor agencies and omitted Answerability entirely, then explained why in our own framework’s vocabulary when we asked. The published note names exactly which Content, Retrieval, and Trust signals were missing, and which ones moved on the re-test.
Engagements where the client shipped the priority work orders typically see meaningful citation movement within the first monthly cycle of Visibility Intelligence.
The framework, the engine set, and the scoring rubric are standing protocol. Every other element — the buyer archetypes, the 60 prompts, the URL ledger, the competitor landscape, the work orders, the 30-day roadmap — is built from your domain, your buyers, and your category. The May 2026 Answerability Index pilot makes this concrete: the same six-prompt protocol produced a 0.38 inter-engine overlap on commercial insurance brokers, 0.85 on B2B SaaS and industrial manufacturing, and 0.24 on personal injury law — three different competitive structures, three different sets of work orders. Frozen categories need an entity-clarity and corroboration-density push; molten categories need answer-pattern building; fragmented categories need engine-specific corroboration sets.
If we ran the audit against your two closest competitors next week, you’d get three reports that look related in chrome and unrelated in content.
It’s almost always the entity graph, not the audit. Engines that lean on Wikidata, the Knowledge Graph, and verified business listings — Gemini in particular — won’t surface a company that isn’t in those graphs, no matter how good the on-site content is. The May 2026 Answerability Index wealth-management edition makes the asymmetry concrete: ChatGPT was the systematic outlier across all six HNW buyer prompts, tilting heavily toward trust-bank and private-bank brands (Bessemer Trust, Rockefeller Capital, J.P. Morgan Private Bank) while the other four engines leaned independent RIA (Creative Planning, Mariner Wealth, Cresset Asset Management). The engines weight different parts of the corroboration apparatus differently. We surface this explicitly in the per-engine analysis and it usually becomes the highest-leverage line item on the roadmap: which graph nodes your firm is missing, and which engines weight those nodes most heavily.
Yes — use Read the sample report. We send a real diagnostic to your work email, anonymized where contractually required. No subscription, no follow-up sequence, no qualification gate. The default sample is the Crestline Pest Control diagnostic — a fictional five-location pest-management firm — rendered against all five real AI engines in May 2026; it walks through the executive summary, the per-engine visibility matrix, the trust-signal gap, the URL-level scoring ledger, and the 30-day work-order queue. The fictional client lets the sample show the full report architecture, including the per-URL scoring annotations that would normally redact under client MNDA. A Crestline Visibility Intelligence cycle-1 delta report ships alongside the diagnostic, so the recurring monthly artifact is visible against the same baseline.
How retrieval systems shape commercial discovery.
Working notes, observed patterns, and methodological ideas behind the diagnostic.
Who currently holds the buyer questions you care about — and where the field is still open.
The three independent gates a citation has to clear — and why your weakest one decides the outcome.
Buyers ask one question. Retrieval systems often expand it into dozens more.
Some firms repeatedly enter AI-generated consideration sets. Others almost never appear.